摘要
《100 Go Mistakes and How to Avoid Them》一本关于 Go 语言中常见错误的书籍,在于介绍和让我们不再陷入这些陷阱当中。书 2022 年 8月出版,国内目前还没有中文版本,花了几周的地铁时间,终于陆陆续续看完了。
涉及的代码仓库:https://github.com/rexyan/100-Go-Mistakes
变量屏蔽
在 Go 语言中,块作用域内声明的变量名可以在内部块中重新声明。这个原则被称为变量屏蔽,容易出现常见的错误。
❌错误代码
1 | var client *http.Client ❶ 声明一个 client 变量 |
我们首先声明一个client变量。然后,我们在两个内部块中使用短变量声明运算符(:=)将函数调用的结果分配给内部client变量,而不是外部变量。因此,外部变量始终为nil。
✅正确代码
正确写法1
1 | var client *http.Client |
正确写法2:我们可以直接将结果赋值给 client, 而不是先分配给一个临时变量
1 | var client *http.Client |
🎡总结
变量屏蔽是指在内部块中重新声明变量名,但我们已经发现这种做法容易出错。禁止屏蔽变量的做法取决于个人口味。例如,有时重用现有的变量名(如错误)可以更方便。
不必要的嵌套
❌错误代码
join 函数拼接两个字符串并在长度大于 max 时返回子串。同时,它还校验 s1 和 s2 参数,以及拼接调用是否返回错误。
1 | func join(s1, s2 string, max int) (string, error) { |
从实现的角度来看,这个函数是正确的。但是嵌套的层级却很多。
✅正确代码
1 | func join(s1, s2 string, max int) (string, error) { |
🎡总结
不应该这样写
1 | if foo() { |
而应该这样写
1 | if foo() { |
同理不应该这样写
1 | if s != "" { |
而应该这么写
1 | if s == "" { |
滥用 init
一个init函数是用来初始化应用程序状态的函数。它不带任何参数,也不返回结果(一个 func() 函数)。当一个包被初始化时,包中的所有常量和变量声明都会被计算。然后,init函数会被执行。例如一下代码:
1 | package main |
例如以下代码中,我们定义了 main 包,又在 main 包中引用了 redis 包,如果 redis 包中存在 init 函数,那么就会先执行 redis 包中的 init,然后再执行 main 包中的 init。最后在执行 main 函数本身。
1 | import ( |
我们可以为每个包定义多个 init 函数。当存在多个 init 函数时,包中每个 init 函数的执行顺序取决于源文件的字母顺序。例如,如果一个包包含 a.go 和 b.go 文件,并且两个文件都有 init 函数,则 a.go 文件的 init 函数首先被执行。
但问题就出在这里,我们有时会依赖同一个包内的多个 init 的执行顺序。这样做可能是危险的,因为源文件可能会被重命名,从而潜在地影响执行顺序。
我们也可以在同一源文件中定义多个init函数
1 | func init() { ❶ 第一个初始化函数 |
有时,我们并不依赖包的中的某个函数,但是需要进行初始化这个包,我们可以使用 _ 操作符来做到:
1 | package main |
另一方面,init 函数它不能够直接被调用,就如以下的例子一样:
1 | package main |
还有一些场景下不适合使用 init 函数,例如:在示例的 init 函数中,我们使用 sql.Open 打开一个数据库。将此数据库作为全局变量使其他函数可以稍后使用。
1 | var db *sql.DB |
首先,在 init 函数中的错误管理是受限的。由于 init 函数不返回错误,要发出错误信号的唯一方法之一是使用 panic,使应用程序停止。其次,另一个重要的缺点与测试有关。如果我们向该文件添加测试,那么init函数将在运行测试用例之前执行,这可能不是我们想要的,因为我们可能就是要测试 init 中连接。最后一个缺点是示例将数据库连接池分配给全局变量,全局变量的坏处就是任何包内的函数都可以修改这个全局变量,并且可能会导致全局变量的测试变得复杂,因为全局变量没有了隔离性。
所以,数据库初始化,并不合适在 init 中进行。数据库的初始化在大多数情况下,我们应该使用一个变量将其封装起来,而不是让它成为全局变量:
1 | func createClient(dsn string) (*sql.DB, error) { ❶ 接受一个数据源名称并返回 *sql.DB 和错误 |
如此封装,就解决了使用 init 带来的缺点了,错误处理的责任由调用者承担,还可以创建集成测试来检查这个函数是否正常工作,并且连接池被封装在函数内部。
❌错误代码
- 同一个包中存在多个 init,我们很依赖 init 的执行顺序(这种情况下 init 的执行顺序和源文件的字母顺序有关)但是这种顺序不能被保证,很容易就会被修改了。
- 直接调用 init 函数
✅正确代码
- 不应该依赖同一个包内的多个 init 的执行顺序
- 如果只想初始化另一个包,可以使用 _ 操作符
- 不应该直接调用 init 函数
- 因为 init 不能很好的处理错误,里面可以使用 panic,但是除非是致命的错误,否则使用会造成程序运行中断
- 不建议在 init 中获取数据库的连接,并将连接对象设置一个全局变量
过度使用 getter 和 setter
在编程中,数据封装往往是为了隐藏对象的内部状态。getters 和 setters 就是提供修改/获取内部对象字段的导出函数。在Go语言中,并没有明确的限制必须要通过 getters and setters 去获取数据。比如 time 标准库中有:
1 | timer := time.NewTimer(time.Second) |
你可以直接修改C变量。
❌错误代码
在 go 中强求使用 Getter 和 Setter。
✅正确代码
在 go 中不强求使用 getter 和 setter。但是当我们,要使用 getter 和 setter 的时候,假设是一个名为 balance 的字段,我们应该遵循这些命名惯例:
- Getter 方法的名称应该为 Balance(而不是 GetBalance)
- Setter 方法应该被命名为 SetBalance
1 | currentBalance := customer.Balance() ❶ getter |
接口污染
接口概念
Go 接口的不同之处在于它们是隐式满足的。没有像 implements 这样的关键字来标记一个对象X实现了接口Y。我们可以拿标准库中的例子:io.Reader和io.Writer。
1 | type Reader interface { |
假设我们需要实现一个函数,其目的是将一个文件内容复制到另一个文件。我们可以创建一个特定的函数,该函数将以两个 *os.Files 作为输入。或者,我们可以选择使用 io.Reader 和 io.Writer 抽象来创建更通用的函数:
1 | func copySourceToDest(source io.Reader, dest io.Writer) error { |
这个函数可以使用*os.File参数(因为*os.File实现了io.Reader和io.Writer),以及任何实现这些接口的其他类型。例如,我们可以创建自己的io.Writer,将数据写入数据库,而代码也将保持不变。这增加了函数的通用性,因此提高了它的可重用性。
另外,我们还可以将细粒度的接口组合在一起,以创建更高级别的抽象。这就是io.ReadWriter的情况,它结合了读取器和写入器的行为:
1 | type ReadWriter interface { |
什么时候使用接口
通用的行为
在sort包中,我们可以找到数十种实现。例如,我们在某个时刻计算一组整数,想要将它们排序,那么我们一定对实现类型感兴趣吗?排序算法是归并排序还是快速排序很重要吗?在许多情况下,我们并不关心。因此,排序行为可以被抽象出来,我们可以依赖sort.Interface。例如 sort 包 中的 Interface 接口:
1 | type Interface interface { |
检查一个集合是否已经排序,就可以用上上面的接口:
1 | func IsSorted(data Interface) bool { // 传入 实现了接口的 data |
解耦
解耦的一个好处可以与单元测试相关。假设我们想实现一个名为 CreateNewCustomer 的方法,用于创建并存储一个新客户,不解耦的情况下, 我们可能会这么实现:
1 | type CustomerService struct { |
如果我们想要测试这个方法怎么办?因为 CustomerService 依赖于实际的实现 mysql 来存储客户,我们被迫通过集成测试来进行测试,这需要启动一个 MySQL 实例。那如果我们解耦呢:
1 | type customerStorer interface { ❶ 创建一个存储的抽象接口,里面有个 StoreCustomer 方法 |
现在存储客户是通过接口完成的,这使得我们在测试该方法时具有更多的灵活性。可以通集成测试,或者通过单元测试使用模拟对象。
限制行为
假设我们现在已经有了一个 IntConfig 结构体,并且这个结构体有两个方法 Get 和 Set。
1 | type IntConfig struct { |
现在有一个需求是不改动上面的代码,要阻止调用 Set 方法(屏蔽)对 IntConfig 进行更新。这时我们可以创建一个新的接口,里面只有一个 Get 方法:
1 | type intConfigGetter interface { |
这样,就是 IntConfig 实现了 intConfigGetter 接口了。并且我们只提供了 Get 方法。在使用的时候,我们可以这样使用:
1 | type Foo struct { |
接口污染
Interface 污染则代表了代码中充斥着无用的抽象,难以理解。
接口的目的是创建抽象。当编程遇到抽象时,主要注意点是要记住抽象应该被发现,而不是被创造。这是什么意思?这意味着如果没有立即需要,我们不应该在我们的代码中开始创建抽象。我们不应该用接口进行设计,而应等待具体的需求。换句话说,我们应该在需要时创建接口,而不是在预见到可能需要时创建接口。
接口应该在哪里
情景1: 接口在生产者端 — 接口与具体实现一同被定义

情景2: 接口在消费者端 — 接口是在使用的地方进行定义的
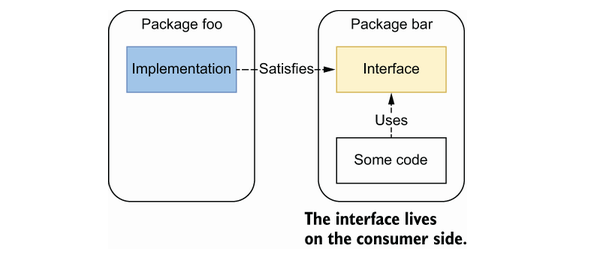
在 C# 或者 Java 中,很常见的模式是情境1。但是在 Go 中,我们还可能或者更应该存在情境2,因为 Go 语言的接口是隐式满足的。
例如,我们想实现一个包来进行客户的存储和查询。但是呢,规定所有的操作都必须通过接口来进行,如下所示:
1 | package store |
如果采用情景1,那么这么抽象和实现都被定义在了制造者端。但是如前所述,Go 语言中的接口是隐式满足的,在大多数情况下,我们应该发现抽象,而不是创建抽象。这意味着制造者并不需要强制为所有客户端提供特定的抽象。相反,客户端需要决定是否需要某种形式的抽象,并确定其需要的最佳抽象级别。
例如,我们只对 GetAllCustomers 方法感兴趣。在这种情况下,这个客户可以创建一个仅包含单个方法的接口:
1 | package client |
customersGetter只在内部使用,所以可以不导出- 很多人会认为他有循环依赖,其实并没有,因为Go的interface是隐式的。
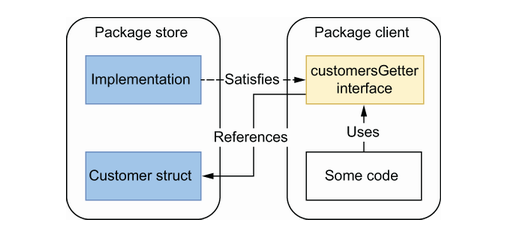
因此,在这种情况下,最好的方法是在生产者侧公开具体实现,让客户端决定如何使用它以及是否需要抽象。
但是在 Go 中,虽然我们推荐情景2 的写法,但也存在情境1 的情况,例如在标准库中。encoding包定义了一些inteface,被子包encoding/json,encoding/binary实现。
返回接口
在许多情况下,在Go语言中返回接口被认为是一种不良实践。例如下面代码中,store 包返回 client 包中的 Store 的接口。这时,store 包就依赖于 client 包。
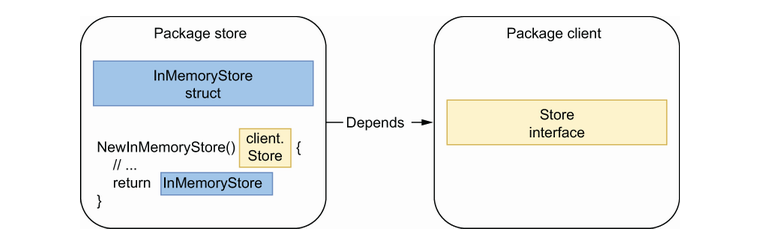
在 store 包中,我们定义了一个实现存储接口的 InMemoryStore 结构体。同时,我们创建了一个NewInMemoryStore 函数来返回一个 Store 接口。这时就存在一个问题,client 包不能再调用NewInMemoryStore 函数,否则会造成循环依赖。一个可能的解决方案是从另一个包中调用该函数,并向 client 包 注入一个Store实现。但这样的代码就会很难理解。所以,结论是:
- 用返回具体实现来代替 interface
- 尽可能的接收 interface 参数
做事要保守,但接受别人的观点要开放。
但是这并不是一直这样的,也会有返回接口的情况,例如:以下函数返回一个导出的结构体 io.LimitedReader。然而,函数签名是一个接口 io.Reader。这和上面我们的建议和结论相违背。io.Reader 是一个前置抽象。它不是由客户端定义的,而是由语言设计者预先了解到这个抽象级别将是有帮助的(例如,关于可重用性和组合性)。所以这种情况下也是对的。
1 | func LimitReader(r Reader, n int64) Reader { |
总的来说,在大多数情况下,我们不应该返回接口而是具体的实现。否则,由于包依赖关系会使我们的设计更加复杂,并且会限制灵活性。
再次强调,结论与前面的部分类似:如果我们知道(而不是预见)抽象对客户有帮助,我们可以考虑返回接口。否则,我们不应该强迫抽象;它们应该由客户端发现。
any
Go 1.18 的推出后,预定义的 any 类型成为了空接口的别名;因此,所有 interface{} 的出现都可以用 any 来替代。
❌错误代码
1 | package store |
通过使用any,我们失去了Golang作为静态类型语言的一些好处。相反,我们应该避免使用任何类型,并尽可能使我们的函数签名明确。
✅正确代码
1 | func (s *Store) GetContract(id string) (Contract, error) { |
🎡总结
任何情况下都不可以使用 any 吗?其实不是的,例如在 encoding/json 包中,因为我们可以将任何类型编组,所以 Marshal 函数接受一个任意参数
1 | func Marshal(v any) ([]byte, error) { |
另一个例子在 database/sql 包中。 如果查询是参数化的(例如,SELECT * FROM FOO WHERE id = ?),则参数可以是任何类型。 因此,它也使用任何参数。
1 | func (c *Conn) QueryContext(ctx context.Context, query string, |
总的来说,该用的时候使用,不用能让代码的表达能力更清楚,更能表达代码的作用。
什么时候用泛型
什么是泛型
例如有以下代码,获取 map 中的所有key。但是呢 map 有不用类型
1 | func getKeys(m any) ([]any, error) { ❶ 接受并返回任何参数 |
当我们想添加一个 case 时,需要重复 range 循环。与此同时,这个函数现在接受了 any 类型,这意味着我们失去了作为强类型语言Go的一些优势。
以下是泛型示例:
1 | func foo[T any](t T) { ❶ T 是一个类型参数 |
使用场景
以下是使用泛型重写 getKeys 的示例:
1 | func getKeys[K comparable, V any](m map[K]V) []K { ❶ 键是可比较的,而值可以是任何类型 |
在Go中,Map 的键不能是任何类型。例如,我们不能使用切片:
1 | var m map[[]byte]int |
这段代码会导致编译错误:无效的 map 键类型 []byte。在这里,要求是键类型必须是可比较的(我们可以使用==或!=)。因此,我们将 K 定义为可比较的类型,而不是任何类型。我们想将其限制为int或string类型。我们可以通过以下方式定义自定义约束:
1 | type customConstraint interface { |
类型参数的最后一项需要注意的是,它们不能用于方法参数,仅能用于函数参数或方法接收器,例如以下代码:
1 | type Foo struct {} |
在以下场景中,泛型比较用得多:
数据结构-例如实现二叉树、链表或堆时,我们可以使用泛型来分离元素类型。
与 slices(切片)、 maps(映射)和任何类型的 channels(通道)一起使用的函数——例如,合并两个 channels 的函数将适用于任何类型的 channel。因此,我们可以使用类型参数来分离 channel 类型:
1
2
3func merge[T any](ch1, ch2 <-chan T) <-chan T {
// ...
}将行为和类型分离
例如有一个接口:
1
2
3
4
5type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}用泛型实现上面接口
1
2
3
4
5
6
7
8type SliceFn[T any] struct { ❶ 使用类型参数
S []T
Compare func(T, T) bool ❷ 比较两个T元素
}
func (s SliceFn[T]) Len() int { return len(s.S) }
func (s SliceFn[T]) Less(i, j int) bool { return s.Compare(s.S[i], s.S[j]) }
func (s SliceFn[T]) Swap(i, j int) { s.S[i], s.S[j] = s.S[j], s.S[i] }因为SliceFn 结构实现了 sort.Interface,所以我们可以使用 sort.Sort(sort.Interface) 函数对提供的切片进行排序。
1
2
3
4
5
6
7
8
9s := SliceFn[int]{
S: []int{3, 2, 1},
Compare: func(a, b int) bool {
return a < b
},
}
sort.Sort(s)
fmt.Println(s.S)
[1 2 3]
结构体内嵌
Go在结构体中提供了内嵌类型的方式,会出现一些不在预期内的情况。
1 | type Foo struct { |
Foo.Bar就是一种内嵌类型,允许Foo直接调用Bar的方法。
❌错误代码
我们下面看一种错误的内嵌使用方式,我们想要在内存中并发操作map:
1 | type InMem struct { |
因为sync.Mutex是内嵌类型,我们可以使用Lock和Unlock方法,但是这两个方法也同样是导出方法,可以被外部调用。
1 | m := inmem.New() |
Mutex 在大多数情况下是我们想要封装在结构体中并对外部客户端隐藏的内容。因此,在这种情况下我们不应该将其作为嵌入字段。
✅正确代码
所以我们应该改为:
1 | type InMem struct { |
🎡总结
我们来看一个使用内嵌比较适合的场景,我们想编写一个自定义日志记录器,其中包含一个io.WriteCloser并公开两种方法:Write和Close。如果未嵌入io.WriteCloser,则需要编写如下代码:
1 | type Logger struct { |
但是,当我们使用内嵌的时候:
1 | type Logger struct { |
上述示例防止了仅仅为了转发调用而实现的这些附加方法。
那内嵌和集成有什么区别呢:
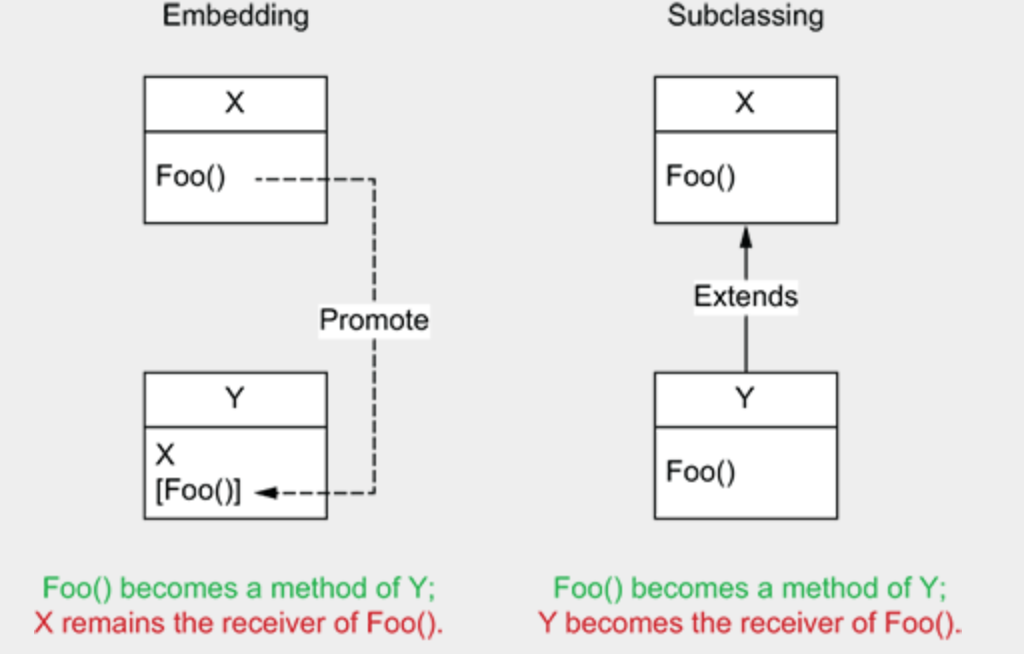
通过嵌入,Foo 的接收者仍然是 X。然而,通过继承,Foo 的接收者变成了子类 Y。嵌入是关于组合,而非继承。
函数的选项模式
当我们设计API的时候经常会遇到一个问题:怎么去处理一些可选的配置项?效率的解决这个问题就可以让我们的API使用起来更舒适。举个例子,当我们需要设计一个函数去创建一个HTTP服务时,起初需要两个入参:地址以及端口,我们提供了以下方式:
1 | func NewServer(addr string, port int) (*http.Server, error) { |
一开始都很方便,渐渐的,客户端开始抱怨说怎么无法设置超时时间。这时候我们就会发现:当我们想要增加一个参数时,客户端就无法兼容原来的调用NewServer方式了。那我们怎么去设计一个API友好型的函数呢?比较通用的方式就是把所有的配置项设置成一个struct,然后只接收一个struct参数。而我们这一章要讲的则是另一种方式functional options pattern:
- 私有结构体涵盖配置参数:
options - 每个可选项都会返回同类型:
type Option func(options *options) error
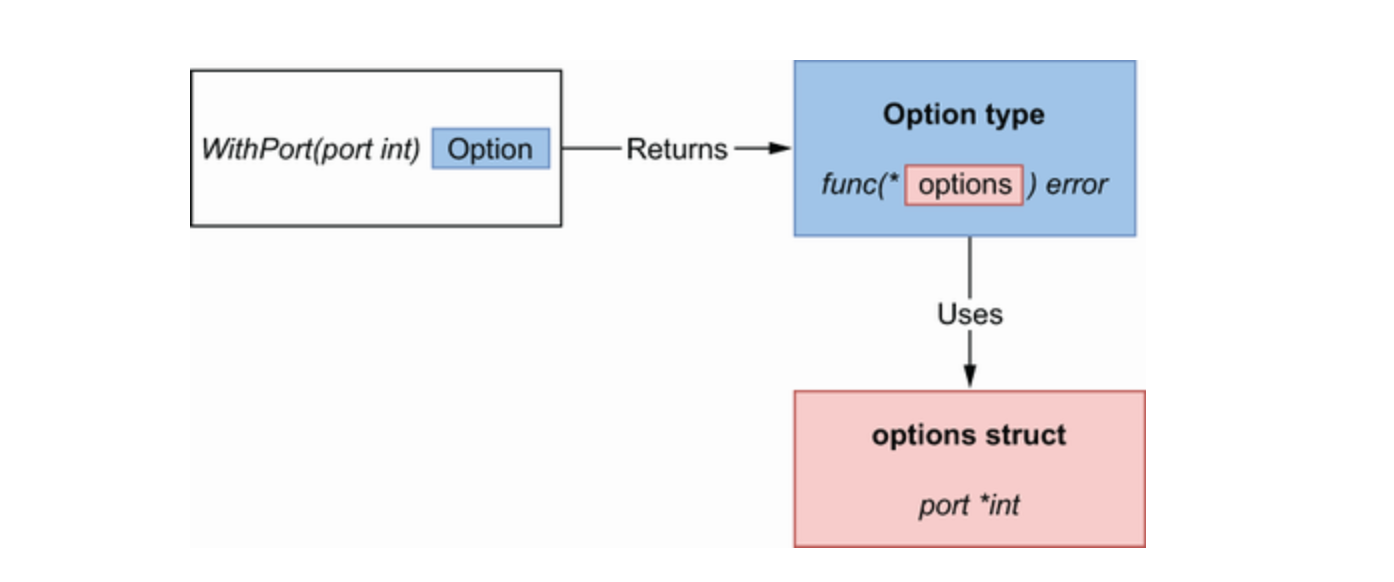
1 | type options struct { ❶ 配置结构体 |
WithPort 返回一个闭包。闭包是一个匿名函数,它引用了外部变量,这里是引用了 port 参数。
闭包考虑了选项类型并实现了端口验证逻辑。每个配置字段都需要创建一个公共函数(按惯例以 With 前缀开头),其中包含类似的逻辑:必要时验证输入并更新配置结构。再来看看怎么应用这些配置:
1 | func NewServer(addr string, opts ...Option) ( ❶ 接收不定数量的 Option 参数 |
使用的时候,可以这么写:
1 | server, err := httplib.NewServer("localhost", |
如果想使用默认参数,则可以不传递 Withxx 函数
1 | server, err := httplib.NewServer("localhost") |
项目结构
Go语言的维护者没有关于如何在Go中构建项目的强烈惯例。然而,多年来已经出现了一个布局:project-layout
在 Go 中,没有子包的概念。然而,我们可以选择在子目录中组织软件包。如果我们看一下标准库,net 目录就是这样组织的:
1 | /net |
net 既是一个包又是一个包含其他包的目录。
粒度是另一个需要考虑的重要因素。我们应该避免拥有数十个仅包含一个或两个文件的纳米级包。相反地,我们也应该避免过大的包,这将淡化包名称的意义。
包名应该简短、简明、富有表现力,在约定中应该是一个小写单词。
utility 包
本节讨论一种常见的坏习惯:创建共享包,例如 utils、common 和 base等
例如:我们有以下代码,并将其放在 util 包中
1 | package util |
使用方式如下:
1 | set := util.NewStringSet("c", "a", "b") |
这里的问题在于 util 没有意义。我们可以称之为 common、shared 或 base,但它仍然是一个毫无意义的名称,无法提供任何关于该软件包属性的指示。
我们应该创建一个更有表现力的包名,比如stringset,而不是一个实用程序包。例如:
1 | package stringset |
1 | set := stringset.New("c", "a", "b") |
我们甚至可以再进一步。不是暴露实用函数,而是创建一个特定类型,并以此方式作为方法公开:
1 | package stringset |
1 | set := stringset.New("c", "a", "b") |
变量名和包名冲突
当变量名称与现有包名称冲突时,会发生包冲突。让我们看一个具体的示例:
1 | package redis |
使用时,尽管包名称为 redis,但在 Go 中创建一个名为 redis 的变量也完全有效
1 | redis := redis.NewClient() ❶ 从 redis 包调用 NewClient |
这里 redis 变量名与 redis 包名发生了冲突。尽管这是被允许的,但应该避免发生这种情况。实际上,在 redis 变量的作用域范围内,redis 包将不可访问。
第一种解决方式:使用不同的变量名
1 | redisClient := redis.NewClient() |
第二种解决方式:使用别名
1 | import redisapi "mylib/redis" ❶ 创建 redis 包的别名 |
代码文档
每个导出的元素必须进行文档化。无论是结构体、接口、函数还是其他的东西,只要它被导出,就必须进行文档化。约定俗成的做法是添加注释,以导出元素的名称开头
1 | // Customer is a customer representation. |
每个注释应该是一个以标点符号结尾的完整句子。并且注释的内容,应该强调函数的意图而不是它如何实现。
可以使用 // Deprecated: 注释的方式标记导出的元素为过时元素。
当为常量时,应该这么使用注释
1 | // DefaultPermission is the default permission used by the store engine. |
第一行注释文档说明了目的,第二行文档说明了实际的内容。
当为包的时候,应该对每个包进行文档编写。惯例是以 // Package 为开头,后跟包名称的注释
1 | // Package math provides basic constants and mathematical functions. |
一个包的文档可以在任何 Go 文件中完成,这个没有规定。通常情况下,我们应该将包文档放在与包同名的相关文件中,或者放在一个特定的文件,比如doc.go中。
与声明不相邻的注释将会被省略。例如,以下版权注释将不会在生成的文档中显示
1 | // Copyright 2009 The Go Authors. All rights reserved. |
代码检查工具
在 “变量屏蔽” 中,我们讨论了变量重名潜在的错误。我们可以使用 vet 和 shadow 来发现这种情况
1 | package main |
vet 已经内置了,shadow 需要先安装1
2
3
4 go install golang.org/x/tools/go/analysis/passes/shadow/cmd/shadow ❶ 安装 shadow
go vet -vettool=$(which shadow) ❷ 使用
./main.go:8:3:
declaration of "i" shadows declaration at line 6 ❸ 检测到变量屏蔽
代码检查常用工具:
https://golang.org/cmd/vet/ —A standard Go analyzer
https://github.com/kisielk/errcheck —An error checker
https://github.com/fzipp/gocyclo —A cyclomatic complexity analyzer
https://github.com/jgautheron/goconst —A repeated string constants analyzer
代码格式化工具:
https://golang.org/cmd/gofmt/ —A standard Go code formatter
https://godoc.org/golang.org/x/tools/cmd/goimports —A standard Go imports formatter
https://github.com/golangci/golangci-lint
八进制字面量的误解
1 | sum := 100 + 010 |
我们可能期望这段代码会打印出 100 + 10 = 110 的结果。但实际上它打印出了 108。
在Go语言中,以0开头的整数字面值被认为是八进制整数,因此八进制数10 等于十进制数8。因此,前面例子中的总和等于100 + 8 = 108。
八进制整数在不同的场景中非常有用。例如,假设我们想要使用 os.OpenFile 打开一个文件。此函数需要传递一个uint32作为权限。如果我们想匹配 Linux 权限,我们可以传递一个八进制数,而不是一个十进制数,以提高可读性:
1 | file, err := os.OpenFile("foo", os.O_RDONLY, 0644) |
还可以在零后面添加一个o字符(小写字母o),使用 0o 而不仅仅是 0 作为前缀,二者表达意思是相同的,但它可以帮助使代码更清晰。为了提高可读性并避免未来代码读者的潜在错误,应明确使用0o前缀来表示八进制数。
1 | file, err := os.OpenFile("foo", os.O_RDONLY, 0o644) |
其他字面量的表达方式:
- 二进制——使用 0b 或 0B 前缀(例如,0b100 等于 10 进制中的 4)
- 十六进制——使用0x或0X前缀(例如,0xF等于10进制中的15)
- 虚数 - 使用 i 后缀(例如,3i)
整数溢出
Go语言提供了10种整型类型。其中包括4种有符号整型类型和4种无符号整型类型,如下表所示
| 有符号整数 | 无符号整数 |
|---|---|
| int8 (8 bits) | uint8 (8 bits) |
| int16 (16 bits) | uint16 (16 bits) |
| int32 (32 bits) | uint32 (32 bits) |
| int64 (64 bits) | uint64 (64 bits) |
另外两种整数类型是最常用的:int 和 uint。这两种类型的大小取决于系统:在 32 位系统上是 32 位,在 64 位系统上是 64 位。
溢出的例子:
假设我们想要将 int32 初始化为最大值,然后递增它。这段代码的行为应该是什么?
1 | var counter int32 = math.MaxInt32 |
该代码可以编译,并且在运行时不会发生 panic。但是,counter++ 语句会生成整数溢出:
1 | counter=-2147483648 |
整型溢出是指算术运算产生一个值,超出一个给定字节数量所能表示的范围。一个 int32 类型使用 32 个比特位表示。以下是最大 int32 值(math.MaxInt32)的二进制表示:
1 | 01111111111111111111111111111111 |
由于 int32 是有符号整数,左侧的位表示整数的符号:0 表示正数,1 表示负数。如果我们将这个整数递增,就没有空间来表示新值。因此,这导致整数溢出
1 | 10000000000000000000000000000000 |
正如我们所看到的,符号位现在等于1,表示为负数。这个值是用32位表示的有符号整数的最小可能值。
在 Go 中,编译时能检测到的整数溢出会生成编译错误。例如:
1 | var counter int32 = math.MaxInt32 + 1 |
然而,在运行时,整数溢出或下溢是静默的;这不会导致应用程序崩溃。必须记住这种行为,因为它可能会导致讨厌的错误(例如,整数的增量或正整数的加法导致负结果)
递增时检测整数溢出
如果我们想要在基于定义大小的类型(int8,int16,int32,int64,uint8,uint16,uint32或uint64)上进行增量操作时检测整数溢出,我们可以将该值与math常数进行比较。例如,对于int32:
1 | func Inc32(counter int32) int32 { |
此函数检查输入值是否已等于 math.MaxInt32。如果是那样,我们就知道 Inc32 增量操作是否会导致溢出了。
对于int:
1 | func IncInt(counter int) int { |
对于 uint:
1 | func IncUint(counter uint) uint { |
在加法中检测整数溢出
1 | func AddInt(a, b int) int { |
在乘法中检测整数溢出
乘法运算处理起来稍微有点复杂。我们需要对最小整数math.MinInt进行检查:
1 | func MultiplyInt(a, b int) int { |
首先,我们需要测试其中一个运算数是否等于0、1或math.MinInt。然后,我们将乘法结果除以b。如果结果与原因数(a)不相等,则表示发生了整数溢出。
简而言之,在Go语言中,整数溢出(和下溢)是不带提示的操作。如果我们想要检查溢出以避免不明错误,我们可以使用本节中描述的实用程序函数。此外,请记住,Go语言提供了一个用于处理大型数字的包:math/big。如果int类型不够用,这可能是一个选择。
浮点
在Go语言中,除了虚数之外,有两种浮点数类型:float32和float64。浮点数的概念是为了解决整数的主要问题:无法表示分数值。为了避免出现意外情况,我们需要知道浮点数运算是实数运算的近似值。
1 | var n float32 = 1.0001 |
我们可能期望这段代码打印出 1.0001 * 1.0001 的结果为 1.00020001,是不是对的呢?然而,在大多数 x86 处理器上运行它会打印出 1.0002。那我们该如何解释呢?
math.SmallestNonzeroFloat64(float64最小值)和 math.MaxFloat64(float64最大值)之间有无限数量的实数值。相反,float64类型具有有限数量的位数:64。因为将无限值装入有限空间是不可能的,所以我们必须使用近似值。因此,我们可能会失去精度。同样的逻辑也适用于float32类型。
在Go中,浮点数遵循IEEE-754标准,其中一些位表示余数,另一些位表示指数。余数是一个基础值,而指数是应用于余数的乘数。在单精度浮点类型(float32)中,8个位表示指数,23个位表示余数。在双精度浮点类型(float64)中,分别为11个位和52个位的指数和余数。剩余一个位用于表示符号。
标记(sign) —— 表示正负
指数(exponent) —— float32(8位) 、float64(11位)
尾数(mantissa) —— float32(23位) 、float64(52位)
公式为:sign * 2^exponent * mantissa,例如:在float32中表示1.0001

一旦我们意识到 float32 和 float64 是近似值。在使用 == 运算符比较两个浮点数可能会导致不准确。相反,我们应该比较它们的差异,以查看它是否小于某个小错误值。例如,testify库 具有InDelta函数,以断言两个值是否彼此之间差值在给定的delta内。
浮点运算的结果取决于实际处理器。大多数处理器都有浮点单元(FPU)来处理这种计算。不能保证在一台机器上执行的结果与具有不同FPU的另一台机器上执行的结果相同。
Go 还拥有三种特殊的浮点数:
- 正无穷
- 负无穷
- NaN
1 | var a float64 |
我们可以使用math.IsInf 来检查一个浮点数是否为无穷大,使用math.IsNaN来检查它是否为NaN。
误差还可以在浮点数的计算中积累,有两个函数以不同的顺序执行相同的操作序列。在我们的例子中,f1首先将float64初始化为10,000,然后重复将1.0001加到结果中(n次)。相反,f2按相反的顺序执行相同的操作(在末尾加上10,000)
1 | func f1(n int) float64 { |
结果误差如下:
| n | Exact result | f1 | f2 |
|---|---|---|---|
| 10 | 10010.001 | 10010.099999999993 | 10010.001 |
| 1k | 11000.1 | 11000.099999999293 | 11000.099999999982 |
| 1m | 1.0101e+06 | 1.0100999999761417e+06 | 1.0100999999766762e+06 |
n越大,误差越大。然而,我们也可以看到,f2的精度比f1更好。结论是,当进行一系列加减操作时,我们应该将具有相似数量级的值进行分组,然后再进行加减运算,以便先进行相同数量级的加减运算,最后再进行数量级不同的加减操作。因为f2加了一万,所以它最终会得到比f1更准确的结果。
另一个例子是乘法的分配律:
1 | a := 100000.001 |
准确的结果是200,030.002。因此,第一次计算具有最差的准确性。实际上,当进行浮点数加法、减法、乘法或除法的计算时,我们必须先完成乘法和除法运算以获得更好的准确性。有时,这可能会影响执行时间(在前面的例子中,需要三个操作而不是两个)。在这种情况下,需要在准确性和执行时间之间做出选择。
总结:
- 在比较两个浮点数时,检查它们的差异是否在可接受的范围内。
- 在进行加法或减法运算时,将具有相似数量级的运算进行分组,以提高精度。
- 为了保证准确性,如果一系列操作需要进行加减乘除,应先执行乘法和除法运算。
切片长度和容量
length表示当前的长度,capacity表示容量。如果两者相等,再append就会触发扩容。如果切片的容量小于 1,024 个元素,那么切片会先按照两倍扩充,之后再按照 25% 的速度扩充。
切片初始化
在使用make初始化一个切片时,我们必须提供长度和可选容量。忘记传递这两个参数中的任一个适当的值都是一个普遍的错误。
假设我们想要实现一个转换函数,将一个 Foo 切片映射为一个 Bar 切片,并且两个切片具有相同数量的元素。这是第一种实现:
1 | func convert(foos []Foo) []Bar { |
一开始,bars 是空的,所以添加第一个元素会分配一个大小为1的数组。每次支持数组满了,Go会创建另一个数组,将容量加倍。当我们添加第三个元素、第五个元素、第九个元素时,因为当前数组已满,所以会再次创建另一个数组的逻辑会重复出现多次。
假设输入的 foos 超过 1,000个元素,这个算法将分配10个数组(每次按照两倍扩容),并在总共从一个数组复制超过1,000个元素。这导致 GC 需要额外的工作来清理所有这些临时数组。
我们来看看第二种写法:
1 | func convert(foos []Foo) []Bar { |
或者直接分配长度,而不是容量
1 | func convert(foos []Foo) []Bar { |
因为我们使用长度初始化了切片,n个元素已经被分配并初始化为Bar的零值。因此,我们不是使用append,而是使用bars[i]。
比较三个方案,当我们不断分配数组和复制元素时,第一个基准测试比另外两个慢了近400%。比较第二个和第三个解决方案,第三个方案快了约4%,因为我们避免了对内置的append函数的重复调用,这与直接赋值相比有一些开销。使用切片的下标来操作切片虽然比 append 要快,但是在可读性上有所缺失,特别是代码逻辑比较复杂的时候,我们可以在其中进行取舍,找到合适自己的。
nil 切片和 empty 切片
定义:
- 如果一个 slice 的长度为 0,它就是空的。
- 如果一个切片等于nil,那么它就是nil。
猜猜以下代码的输出是什么:
1 | func main() { |
以上四种创建切片的方式,分别适合在什么场景下使用呢:
var s []string不确定最终长度并且 slice 可以为空时s = []string(nil)作为语法糖创建一个 nil slices = []string{}在有初始化元素的时候使用s = make([]string, 0)长度已知
结论:
一个 nil slice 和一个空的 slice 的主要区别之一在于分配。初始化一个 nil slice 不需要分配任何内存空间,而空的 slice 则不是这种情况。
无论切片是否为 nil,调用 append 内置函数都能正常工作。
1
2var s1 []string
fmt.Println(append(s1, "foo")) // [foo]当方法返回切片的时候,如果可能,应该返回一个 nil slice,而不是一个空切片。例如以下代码:
1
2
3
4
5
6
7
8
9
10func f() []string {
var s []string // nil 切片
if foo() {
s = append(s, "foo")
}
if bar() {
s = append(s, "bar")
}
return s // 如果上述 if 都不成立,那么返回一个 nil 切片。
}一些包切分 nil 切片和 空切片,比如在 encoding/json 包中就是如此。一个空的切片会被序列化成一个 null 元素,而一个非空的空切片会被序列化成一个空数组。还有在使用
reflect.DeepEqual比较一个 nil 和一个非 nil 的空切片时,将会返回 false。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20var s1 []float32 ❶ nil 切片
customer1 := customer{
ID: "foo",
Operations: s1,
}
b, _ := json.Marshal(customer1)
fmt.Println(string(b))
s2 := make([]float32, 0) ❷ 空切片
customer2 := customer{
ID: "bar",
Operations: s2,
}
b, _ = json.Marshal(customer2)
fmt.Println(string(b))
"""
{"ID":"foo","Operations":null}
{"ID":"bar","Operations":[]}
"""
检查切片是否为空
判断一个切片是否包含元素的惯用方法是什么?
以下代码是个错误示例:
1 | func handleOperations(id string) { |
上述代码中, operations!= nil 将始终为 true。因为我们创建一个空切片。
我们有两种解决方案:
方案1: 当 id == "" 时,返回 nil 而不是创建的 空切片
1 | func getOperations(id string) []float32 { |
方案2: 检查切片的长度
1 | func handleOperations(id string) { |
因此,不管切片是 nil 还是空,长度总是为 0。所以检查长度是判断一个切片是否包含元素的惯用方法。这个规则同样适用于 map,要检查 map 是否为空,应该检查其长度,而不是判断它是否为 nil。
copy 切片
1 | src := []int{0, 1, 2} |
上述代码中,打印的 dst 值为 []。src 是一个长度为 3 的切片,而 dst 是一个长度为 0 的切片,因为它被初始化为它的零值。因此,copy 函数只会复制最少数量的元素(在 0 和 3 之间):在这种情况下是 0。最终得到一个空的切片。所以,复制到目标切片的元素数量取决于以下两者中的最小值
- 源切片的长度
- 目标切片的长度
正确代码如下:
1 | src := []int{0, 1, 2} |
还有一种方案是使用 append
1 | src := []int{0, 1, 2} |
slice 共享底层数组带来的问题
由于 slice 底层的 data 指向的同一块连续内存,所以当我们在切片然后再进行 append 的时候,可能会修改到底层的数组,从而影响整个 slice。
1 | s1 := []int{1, 2, 3} |
例如:下面的示例中,我们使用三个元素初始化一个切片,并仅将前两个元素传递给一个函数。然后在 f 中调用 append,它将会更新切片的第三个元素,即使我们只传递了两个元素。
1 | func main() { |
第一种解决方法:复制切片,传递切片的副本
1 | func main() { |
第二种方法:使用完整切片表达式 s [low:high:max]。 此语句创建一个类似于使用s [low:high]创建的切片,只是所得到的切片容量等于max-low。
1 | func main() { |
🎡总结
如果从一个切片生成一个子切片,但是如果生成的子切片长度小于其容量,则 append 到子切片的数据可能会修改原始切片。为了限制可能副作用的范围,我们可以 copy 出一个切片副本,或使用完整的切片表达式来解决这种问题。
切片内存泄漏
切片容量导致的内存泄漏
1 | func consumeMessages() { |
上述代码运行会非常消耗内存,因为使用 msg[:5] 进行切片操作可以创建一个长度为 5 的切片。然而,它的容量仍与初始切片相同。即使最终 msg 未被引用,其余元素仍会被分配在内存中。
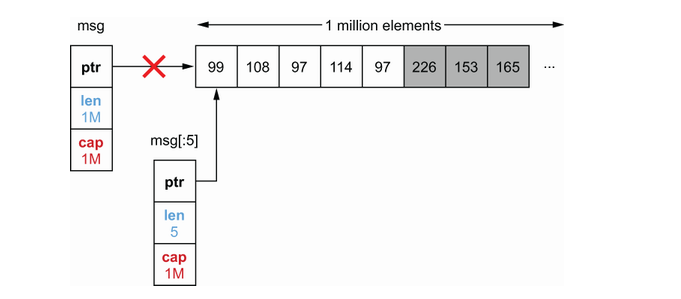
新的循环之后,msg不再使用。然而,msg[:5]仍然会使用它的底层数组。切片的底层数组仍包含 100万字节。因此,如果我们将1,000条消息保存在内存中,我们将持有大约1 GB而不是大约5 KB的空间。
解决方法:
我们可以复制一个切片,而不是对 msg 进行切片操作来解决这个问题。因为我们执行 copy,所以无论接收到的消息大小如何,msgType 都是一个长度为5、容量为5的切片。因此,我们仅存储每个消息类型的5个字节。
1 | func getMessageType(msg []byte) []byte { |
值得注意的是,如果我们使用完整的切片表达式,则还是会存在内存泄漏的情况,即不会释放底层数组:
1 | func getMessageType(msg []byte) []byte { |
切片与指针导致的内存泄漏
定一个结构体,其中包含一个字节切片
1 | type Foo struct { |
1 | func main() { |
结果如下:
1 | 83 KB |
原因是,在使用切片时,如果元素是指针或带有指针字段的结构体,则元素不会被垃圾回收器回收。在我们的示例中,因为Foo包含一个切片(切片是基于一个底层数组的指针),所以即使这些 998 个元素无法访问,只要keepFirstTwoElementsOnly 返回的变量被引用,它们仍然会留在内存中。
第一种解决方法是,再次创建一个切片副本。
1 | func keepFirstTwoElementsOnly(foos []Foo) []Foo { |
由于我们复制了切片的前两个元素,垃圾回收器知道剩下的998个元素将不再被引用,因此现在可以进行回收。
第二种解决方法是,将剩余的切片元素明确的标记为 nil。因此,GC 可以回收底层 998个不使用的数组空间。
1 | func keepFirstTwoElementsOnly(foos []Foo) []Foo { |
🎡总结
- 在对大的 slice 或者数组进行切片操作时,可能会导致高内存消耗。剩余的空间不会被垃圾回收机制回收,因此即使我们只使用了其中的几个元素,我们仍然可能会占用很大的底层数组。使用 copy slice 的方式是避免这种情况的解决方案。
- 当我们使用切片操作与指针或具有指针字段的结构体时,GC不会回收切片剩下的这些元素。在这种情况下,可以执行 copy 或明确标记剩余元素字段为空值来解决问题。
低效的 map 初始化
map 原理
map 是基于哈希表数据结构的。哈希表是一个桶的数组,每个桶是一个指向键值对数组的指针。每个桶的大小固定为8个元素。

每个操作(读取、更新、插入、删除)都是通过将键与数组索引关联来完成的。这一步依赖于哈希函数。由于我们希望该函数始终返回相同的桶,因此该函数是稳定的。例如,哈希函数作用在 two 上返回 0;因此,该元素存储在由数组索引 0 引用的桶中。
如果我们插入另一个元素,哈希函数返回相同的索引,则Go将另一个元素添加到同一个桶中。
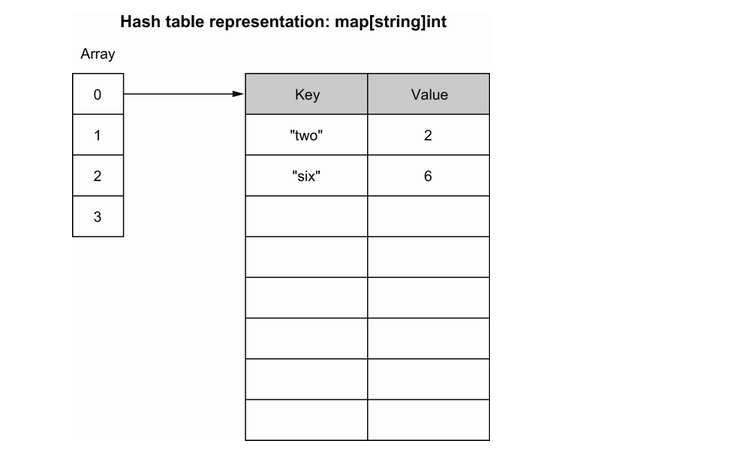
如果插入已经满的桶(桶溢出),Go 会创建另一个8元素的桶并将前一个桶连接到它。

初始化
什么时候 map 会进行扩容呢?
- 桶中的平均项数(称为负载因子)大于一个固定值。该常数等于6.5(但它可能会在将来的版本中改变,因为它是 Go 的内部常数)
- 太多的桶已经溢出(含有超过八个元素)
当 map 扩容时,所有的键都会再次分配到所有的桶中。这就是为什么在最坏情况下,插入一个键可能是一个O(n)操作,其中n是 map 中元素的总数。
也可以像使用 slice 一样,在初始化的时候就指定 map 的大小,如下所示,该 map 是使用足够数量的桶创建的,以存储100万个元素。这样做可以节省大量的计算时间,因为 map 不必动态创建桶并重新平衡。
1 | m := make(map[string]int, 1_000_000) |
同时,指定大小 n 并不意味着创建最多有 n 个元素的映射。我们仍然可以添加超过 n 个元素。
🎡总结
就像切片一样,如果我们事先知道 map 包含的元素数量,我们应该通过提供初始大小来创建它。这样做可以避免潜在的 map 扩容,这对计算机而言是相当沉重的计算,因为它需要重新分配足够的空间并重新平衡所有元素。
map 内存泄漏
我们分配了一个空的map,添加了100万个元素,再删除100万个元素,然后运行了一次垃圾回收。我们还使用runtime.KeepAlive 确保保留对该 map 的引用,以防止其被回收。让我们运行此示例
1 | n := 1_000_000 |
结果如下
1 | 0 MB ❶ |
最终,尽管 GC 收集了所有元素,但堆大小仍为293 MB。因此,内存已经缩小,但与我们的预期不同(还存在内存占用)。这是为什么?
原因在于 map 中桶的数量不可收缩。因此,从 map 中删除元素不会影响现有桶的数量;它只会将桶中的插槽清零。 即 map 只能增长并拥有更多的桶,而不会缩小桶的数量。
有什么解决方法呢?
- 使用复制的方法,定期重新创建当前 map 的副本。例如,每个小时我们可以建立一个新 map,复制所有元素并释放之前的 map,这种方法的主要缺点是在复制之后直到下一次垃圾回收之前,我们可能会在短时间内消耗两倍于当前内存。
- 将 map 类型更改为存储数组指针:map[int]*[128]byte。这并不能解决我们将拥有大量桶的事实; 但是,每个桶条目将保留值的指针大小(64位系统上为8字节,32位系统上为4字节),而不是128字节。
错误的值比较
何时适合使用 ==,还有什么其他方案呢?看一个例子:
1 | type customer struct { |
比较这两个结构体它会打印 true。那么,如果我们对结构体进行轻微修改以添加一个切片字段,会发生什么呢?
1 | type customer struct { |
运行上述代码,会出现无法编译的情况。因为这涉及到 == 和 != 运算符的工作原理。这些运算符无法与切片或 map 一起使用。因此,由于上述结构包含一个切片,所以它无法编译。
slices & maps 是无法通过==比较的。我们可以看下哪些是可比较的:
- Booleans 比较值是否相等
- Numerics (int, float, and complex types) 比较值是否相等
- Strings 比较内容
- Channels 比较是否是同一个make创建的,或者是否都是nil
- Interfaces 比较是否有相同的类型和值 或者是否都是nil
- Pointers 指针比较是否都指向同一个值 或者是否都是nil
- Structs and arrays 比较组成的简单类型
我们更新一下上述的例子,但是将使用 any 来接收值,然后在用于比较,会有什么现象呢?
1 | var cust1 any = customer{id: "x", operations: []float64{1.}} |
现象是可以编译通过,但是无法进行比较,会产生一个错误。
那么有什么解决方法呢?
答案是,我们可以使用 reflect.DeepEqual。该函数通过递归遍历两个值来检查两个元素是否深度相等。它接受的元素包括基本类型以及数组、结构体、切片、map、指针、接口和函数。
1 | cust1 := customer{id: "x", operations: []float64{1.}} |
但是,平均而言,reflect.DeepEqual比==慢大约100倍。如果性能是至关重要的因素,另一个选择是我们自己实现比较的方法。
1 | func (a customer) equal(b customer) bool { |
我们的自定义相等方法大约比 reflect.DeepEqual 快96倍
🎡总结
通常情况下,我们应该记住 “==” 运算符的局限性。例如,它不能用于切片和 map。在大多数情况下,使用reflect.DeepEqual 是一种解决方案,但主要问题是性能不好。
range 循环是值拷贝
range是一个比较方便的控制循环的方式,可用于:
- 字符串
- 数组
- 指针数组
- 切片
- Map
- 接收的channel
我们创建一个 account 结构体,包含一个单一的余额字段
1 | type account struct { |
我们创建一个账户结构的切片,并使用范围循环迭代每个元素。在每次迭代期间,我们会增加每个账户的余额:
1 | accounts := []account{ |
答案是:[{100} {200} {300}]。原因是,因为我们修改的是一份值拷贝,当循环迭代数据结构时,它将每个元素复制到值变量(第二项)中。
在 Go 语言中,都是值的复制。例如一个函数返回一个结构体,在使用一个变量接收,那么变量接收到的将是该结构体的复制。如果我们将返回指针的函数的结果分配给变量,它将执行内存地址的复制。
那么上面问题有什么解决方案呢?
第一种方案是使用索引下标来解决:
1 | for i := range accounts { ❶ 使用索引变量访问切片的元素 |
另一种选择是继续使用 range 循环访问值,但将切片类型修改为帐户指针的切片。
1 | accounts := []*account{ ❶ 将切片类型更新为 []*account |
变量 a 是存储在切片中的 account 指针的副本。由于指针引用同一结构体,所以 a.balance += 1000 语句会更新切片元素。
然而,这种选择有两个主要缺点。首先,它需要更新切片类型(更改为指针)。其次,如果性能很重要,迭代指针切片可能对CPU来说效率较低。
🎡总结
较为推荐的方案是,通过使用 range 循环或经典的 for 循环,来通过索引访问该元素。
range 对象何时被计算
下面代码会陷入死循环吗?
1 | s := []int{0, 1, 2} |
答案是不会,在使用 range 循环时,提供的表达式仅在循环开始之前被评估一次。在这个上下文中,“评估”意味着提供的表达式被复制到一个临时变量中,然后在遍历这个变量。也就是说,上述被遍历的 s 变量会被拷贝到一个临时变量中在进行遍历。
那如果变成下面这样的话, 代码就会陷入循环,永远不会结束。len(s) 表达式在每次迭代期间都会被评估,因为我们不断地添加元素,所以我们永远不会达到终止状态。
1 | s := []int{0, 1, 2} |
在来看一个例子:
1 | ch1 := make(chan int, 3) ❶ 创建一个通道,并在下面的协程中塞入元素 0,1,2 |
在上述代码中,还是会打印 0,1,2。原因在于 range 会评估 ch,将其复制到一个临时变量中。尽管有 ch = ch2 语句,range 仍会继续迭代 ch1 而非 ch2。
同理,在看另一个例子:我们循环数组 a,并将 a 的第三个元素修改为 10,然后我们打印第三个元素。此时输出结果还是2,而不是 10。
1 | a := [3]int{0, 1, 2} ❶ 创建包含三个元素的数组 |
原因还是在于在 range 循环之前 a 变量被评估了一次(也就是复制到了临时变量中,所有后续不管在怎么通过下标更改,其迭代时候的值也不会发生变化)。
那如果我们就是想在迭代的时候进行值的修改,该怎么实现呢,有以下两种方法:
1 | // 方法1 |
range 中使用指针
在使用 for 循环遍历数据时,我们必须记住所有的值都被分配给一个唯一的变量,该变量有一个单一的唯一地址。因此,如果我们在每次迭代中存储引用此变量的指针,那我们会得到指向同一元素的相同指针,即最新的指针。例如:
1 | type Customer struct { |
使用时:
1 | s.storeCustomers([]Customer{ |
上述代码的输出会是三个相同的额值,即 {ID: "3", Balance: 0} 。出现这个问题的原因在于 for 循环遍历数据时,所有的值都被分配给一个唯一的变量,该变量有一个单一的唯一地址。
1 | func (s *Store) storeCustomers(customers []Customer) { |
该指针的最后一次分配是切片的最后一个元素 Customer3 的引用。所以才会出现上述代码中的现象(打印了三个相同的值)
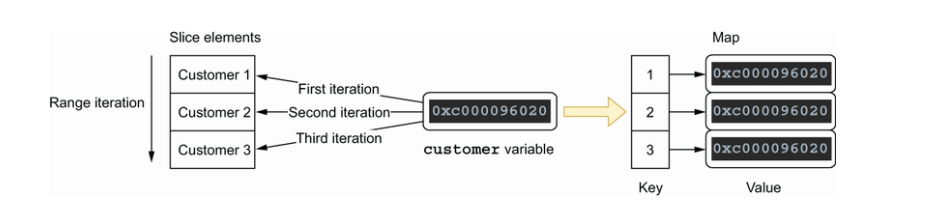
我们可以通过强制在循环内创建一个局部变量或通过索引创建一个引用切片元素的指针来解决这个问题:
1 | func (s *Store) storeCustomers(customers []Customer) { |
1 | func (s *Store) storeCustomers(customers []Customer) { |
map 迭代中的常见问题
- map 的迭代顺序是没有规定的。每次迭代的顺序都是不同的。
- 在迭代过程中更新地图(插入或删除元素)是允许的;它不会导致编译错误或运行时错误。(但是在迭代过程中向 map 添加元素时,在后续迭代中可能会遇到该元素,也可能不会)
1 | m := map[int]bool{ |
下面是运行上述代码可能得到的结果,因为一边遍历,一遍插入元素,所以会出现新插入的元素可能会在后面可见或者不可见。所以影响了最终的结果。1
2
3map[0:true 1:false 2:true 10:true 12:true 20:true 22:true 30:true]
map[0:true 1:false 2:true 10:true 12:true 20:true 22:true 30:true 32:true]
map[0:true 1:false 2:true 10:true 12:true 20:true]
🎡总结
当我们使用 map 时,不应该依靠以下内容:
- 数据按键排序
- 保留插入顺序
- 一个确定的迭代顺序
- 在同一轮迭代中添加元素,并期待后续在迭代中遇到该元素
break 的使用
记住一个 break 的原则:break 语句只会终止最深层的 for、switch 或 select 语句的执行。例如:
1 | for i := 0; i < 5; i++ { |
如果要终止 for ,最符合的方式是使用标签
1 | loop: ❶ 定一个循环标签 |
例如,在下面示例中,我们想要在上下文被取消的时候中断循环:
1 | loop: ❶ 定一个循环标签 |
在循环中使用 defer
defer 语句会被延迟调用 —— 直到包含它 defer 的函数返回时才会调用。这就会导致一些使用上的问题。
常见的错误就是不了解在循环中使用 defer 的后果:
1 | func readFiles(ch <-chan string) error { |
defer 是在包含函数返回时调度函数调用,在这种情况下,defer 调用并不是在每个循环期间执行的,而是在 readFiles 函数返回时才执行。如果 readFiles 不返回,文件描述符将永远保持打开状态,导致内存泄漏。
一种解决的方法是放弃使用 defer,改为手动关闭文件。
另一种解决方法是,将文件的读取操作抽取出来单独封装在一个函数中,在其中实现 defer 的逻辑。
1 | func readFiles(ch <-chan string) error { |
还有一种解决思路是将 readFile 函数设计为一个闭包
1 | func readFiles(ch <-chan string) error { |
这种解决方法本质上和第二种是一致的。
不理解 rune
我们需要先理解两个基础概念:
- 字符集 从名字理解就是字符的集合,比如
Unicode字符集包含了2^21字符。 - 编码 是一个字符列表在二进制种的翻译。比如UTF-8就是一种标准的编码格式,所有的字符都用1-4个字节表示。
代码点(Code Point)是指在字符编码标准中,每个字符所对应的唯一数值。字符编码是一种将字符映射到数字的方式,以便计算机能够处理和存储文本数据。不同的字符编码标准使用不同的方法来分配代码点。
最常见的字符编码之一是 Unicode,它为世界上几乎所有的字符都定义了唯一的代码点。Unicode使用十六进制表示代码点,例如大写字母”A”在Unicode中的代码点为U+0041,其中”U+”表示Unicode代码点的前缀,后面跟着四位十六进制数。— chatgpt
在Unicode中,使用一个概念代码点去表示一个单值。比如汉这个字符的代码点就是U+6C49.使用UTF-8,汉被编码成3个字节:0xE6, 0xB1, 0x89。在Go中,rune就是一个代码点。所以在Go中,一个rune就是int32的别名。
1 | type rune = int32 |
在Go语言中,
rune类型实际上是一个int32类型的别名,用于表示一个Unicode代码点。这使得在处理和操作Unicode字符时更加方便,因为它可以容纳所有可能的Unicode代码点。
2
3
4
5
6
>
>for _, r := range str {
> fmt.Printf("Unicode code point: %U\n", r)
>}
>
字符串 “你好,世界!” 中的每个字符都被转换为对应的Unicode代码点,并使用
%U格式化输出。
字符串迭代和长度
len内置函数并不返回字符数,而是字节数。
1 | s := "汉" |
迭代字符串:
1 | s := "hêllo" ❶ 包含一个特殊的符文:ê |
这是因为,我们并不是迭代每一个符文;相反,我们是迭代每一个符文的起始索引
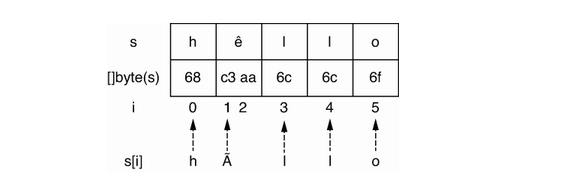
有什么办法可以在迭代的时候正常显示呢?
方法一就是在迭代的时候不使用下标,而是使用变量本身
1 | s := "hêllo" |
方法二是将字符串转换为 rune 切片
1 | s := "hêllo" |
方法二开销比方法一大,因为多了一层类型转换。
🎡总结
如果我们想要迭代一个字符串的符文,我们可以直接在字符串上使用 range 循环。但是我们必须记住,索引不对应于符文索引,而是对应于符文字节序列的起始索引。因为一个符文可以由多个字节组成,如果我们想要访问符文本身,我们应该使用 range 的值变量,而不是字符串中的索引。同时,如果我们想要获取字符串的第i个符文,我们在大多数情况下应该将字符串转换为一个 rune 切片。
trim 函数
Go开发者在使用字符串包时常见的一个错误是混淆 TrimRight 和 TrimSuffix 函数。
TrimRight
1 | fmt.Println(strings.TrimRight("123oxo", "xo")) |
TrimRight 方法倒序迭代每个字符。如果某个字符在提供的字符集中,则该函数会将其删除。如果不在,则函数停止迭代并返回剩余字符串

TrimSuffix
1 | fmt.Println(strings.TrimSuffix("123oxo", "xo")) |
由于123oxo 以xo 结尾,所以此代码将打印出123o。此外,删除末尾后缀并不是一个重复的操作,所以 TrimSuffix(“123xoxo”, “xo”) 返回 123xo。
使用 TrimLeft 和 TrimPrefix 函数处理字符串左侧的空格,与上述原则是相同的。
Trim=TrimLeft + TrimRight。 因此,它会删除集合中包含的所有前置和尾部的字符。
字符串拼接
写一个 concat 函数,使用 += 操作符来连接切片的所有字符串元素
1 | func concat(values []string) string { |
上述函数的问题在于,字符串是不可变的。因此,每次迭代都不会更新 s,而是在内存中重新分配一个新的字符串,这显著影响了该函数的性能。
解决这个问题的方法是使用 strings 包和 Builder 结构体:
1 | func concat(values []string) string { |
WriteString返回一个错误作为第二个输出,但我们有意忽略它。实际上,这个方法永远不会返回非nil错误。那么这个方法返回签名中的错误的目的是什么? strings.Builder 实现了io.StringWriter接口,它包含一个方法:WriteString(s string)(n int,err error)。因此,为了遵守此接口,WriteString必须返回一个错误。
除了上述的 WriteString 外,strings.Builder 还支持其他的追加方法:
- Write —— 追加字节切片
- WriteByte —— 追加单个字节
- WriteRune —— 追加 rune
注意事项:
strings.Builder 内部维护了一个字节切片,每次调用 WriteString 都会导致在这个切片上调用 append,所以,这个结构体不应该同时被使用,因为对 append 的调用会导致竞争条件。其次,如果字符串的未来长度是知道的,我们应该预先分配空间,strings.Builder 公开了一个方法Grow(n int),以保证有 n 个字节的空间。
1 | func concat(values []string) string { |
🎡总结
strings.Builder 是连接字符串列表的推荐解决方案。通常,应该在循环内使用此解决方案。但是如果我们只需要连接几个字符串(如名字和姓氏),使用 strings.Builder 不如使用 += 运算符或 fmt.Sprintf 方案可读性高。
一般原则上,我们可以记住,性能方面,当我们需要连接超过五个字符串时,strings.Builder解决方案更快。即使这个确切的数字取决于许多因素,例如连接的字符串的大小和机器,这也可以成为一个经验法则,帮助我们决定何时选择一个解决方案而不是另一个。此外,我们不应忘记,如果将来字符串的字节数量事先已知,应使用Grow方法来预分配内部字节片。
无效的字符串转换
大部分的 I/O 操作是使用 []byte 完成的。例如,io.Reader、io.Writer 和 io.ReadAll 与 []byte 一起工作,而不是字符串。因此,使用字符串意味着额外的转换,尽管 bytes 包中包含了与 strings 包相同的许多操作。
我们将实现一个 getBytes 函数,它接受一个 io.Reader 作为输入,从中读取数据,并调用一个 sanitize 函数。删除所有前导和尾部空格
1 | func getBytes(reader io.Reader) ([]byte, error) { |
那么,我们的 sanitize 函数该怎么实现呢?接收一个 字符串,然后去除空格?然后再将字符串返回?最终再在 getBytes 中转换为 []byte?
1 | func sanitize(s string) string { |
这么做是有代价的,需要将一个[]byte转换为字符串,去除空格后,再将字符串转换为[]byte。
事实上,在 strings 包中的所有公开函数在 bytes 包中都有相应的替代函数:TrimSpace、Split、Count、Contains、Index 等等。所以我们不必接受一个字符串,然后再返回一个字符串,然后再将结果转换为 []byte。
子字符串内存泄露
要提取字符串的子集,我们可以使用以下语法:
1 | s1 := "Hello, World!" |
但上述函数存在一个问题,这个示例从前五个字节创建一个字符串,而不是前五个符文。因此,在多字节编码符文的情况下,我们不应该使用这个语法。相反,我们应该先将输入字符串转换为 []rune 类型:
1 | s1 := "Hêllo, World!" |
另外一个例子,我们接受日志消息,假设日志最开头是长度为 36 的UUID,然后在是日志内容。现在我们需要保留最新的 n个UUID 的缓存。假设这些日志消息可能非常庞大(高达数千字节)。以下是一种实现方式:
1 | func (s store) handleLog(log string) error { |
上述代码存在内存泄漏吗?是的!log[:36] 将创建一个新字符串,同时也会引用同一后备数组。因此,我们在内存中存储的每个 uuid 字符串将包含不只是36个字节,而是初始日志字符串中的字节(数千字节)
那么怎么解决这个问题呢?
方法一:
1 | func (s store) handleLog(log string) error { |
通过首先将子串转换为[]byte,然后再转换回字符串来,通过这样做,我们创建了一个新的字符串,并且可以防止发生内存泄漏。且 UUID 字符串由仅由36个字节组成的数组支持。
方法二:
Go 1.18 中,标准库还包括了一个使用 strings.Clone 方法返回字符串的新副本的解决方案:
1 | uuid := strings.Clone(log[:36]) |
🎡总结
在使用Go中的子字符串操作时,我们需要记住两件事情。首先,提供的区间是基于字节而不是基于符文数量。其次,子字符串操作可能会导致内存泄漏,因为生成的子字符串将与初始字符串共享相同的后备数组。防止发生这种情况的解决方案是手动执行字符串复制或使用Go 1.18中的strings.Clone。
不知该用哪种类型的方法接收器
在 Go 语言中,我们可以将值或指针接收器附加到方法上。使用值接收器时,Go 会复制该值并将其传递给方法。对对象所作的任何更改都仅限于该方法范围内,原始对象仍保持不变。
1 | type customer struct { |
另一方面,使用指针接收器时,Go将对象的地址传递给方法。从本质上讲,它仍然是一个副本,但我们只复制指针,而不是对象本身(在Go中不存在按引用传递)。对接收器的任何修改都是在原始对象上完成的
1 | type customer struct { |
🎡总结
receiver 必须是一个指针:
如果该方法需要改变接收者。例如如果接收者是一个切片,并且方法需要追加元素
1
2
3
4
5type slice []int
func (s *slice) add(element int) {
*s = append(*s, element)
}如果方法接收器包含无法复制的字段:例如,sync包的类型部分
receiver 应该是指针:
- 如果接收器是一个大对象,使用指针可以使调用更有效,因为这样可以防止进行广泛的复制。
receiver 必须是一个值:
- 如果我们必须强制接收器的不可变性
- 接收者是一个map、函数或管道
- 如果接收器是一个不必被改变的切片
- 如果接收者是一个小的数组或结构体,自然应该是没有可变字段的值类型,例如 time.Time
- 如果接收器是 int、float64 或 string 等基本类型
命名返回参数
命名返回参数简单示例:
1 | func f(a int) (b int) { ❶ 命名结果参数 int b |
什么时候建议我们使用命名结果参数?
假设我们有一个从给定地址中获取坐标的接口,在这种情况下,为了让代码更易于阅读,我们应该使用命名结果参数
1 | type locator interface { |
什么时候建议不使用命名的结果参数?
假设我我们需要将一个 Customer 类型存储到数据库中,这里的将错误参数命名为 err 是没有帮助的。
1 | func StoreCustomer(customer Customer) (err error) { |
因此,何时使用命名结果参数取决于上下文。在大多数情况下,如果不清楚使用它们是否使我们的代码更可读,我们就不应该使用命名结果参数。
还有一种场景是命名结果参数并不会使我们的代码更易于阅读,而是初始化了的命名结果参数可能会非常方便
1 | func ReadFull(r io.Reader, buf []byte) (n int, err error) { |
在这个例子中,命名结果参数并不会真正增加可读性。但是,由于n和err都被初始化为它们的零值,使得实现变得更短了。但另一方面,对于读者来说,这个函数可能有点令人困惑。
命名返回参数意外边界情况
在一些情况下命名的结果参数很有用。但是由于这些结果参数被初始化为它们的零值,如果我们不够小心,使用它们有时会导致微妙的错误。
我们将之前的 getCoordinates 方法修改一下,传入一个 ctx,并在函数内部添加一个验证地址是否有效的逻辑。
1 | func (l loc) getCoordinates(ctx context.Context, address string) (lat, lng float32, err error) { |
这里存在一个问题,if ctx.Err() != nil 的作用域中返回的错误是err。但我们没有为err变量分配任何值。但它是一个命名参数,所以它仍然被分配为错误类型的零值:nil。因此,这段代码总是会返回一个nil错误。但其实 ctx 发生了错误。
一种解决方法是将 ctx.Err() 分配给 err
1 | if err := ctx.Err(); err != nil { |
或者
1 | if err = ctx.Err(); err != nil { |
但不建议第二种方式,因为和上面 if !isValid 的返回风格不一致,在一个方法中,最好不要出现不一致的写法。
nil receiver
我们将会创建一个名为 Customer 的结构体,并实现一个 Validate 方法来进行合理性检查。但我们不想只返回第一个错误信息,我们希望返回整个错误列表。为了实现这个目标,我们需要创建一个自定义错误类型以便传递多个错误信息。
1 | type MultiError struct { |
1 | func (c Customer) Validate() error { |
测试如下
1 | customer := Customer{Age: 33, Name: "John"} |
这个结果可能会相当令人惊讶。Customer 是有效的,但 err!= nil 的条件为真,打印了 <nil>
我们再来看另一个例子:
1 | type Foo struct{} |
foo 被初始化为指针的零值:nil。但是编译这段代码是可以通过的,而且如果我们运行它,它会打印 bar。所以空指针是一个有效的接收器。
回到上上个例子中,m会被初始化为指针的零值:nil。然后,如果所有的检查都有效,提供给 return 语句的参数不是直接的 nil 而是一个 nil指针。因为nil指针是一个有效的接收器,将结果转换为接口不会产生nil值。换句话说,调用Validate的调用者将始终获得一个非nil的错误。
如何解决这个例子呢?最简单的解决方法就是:如果 m 不是 nil,那就返回它。
1 | func (c Customer) Validate() error { |
使用文件名作为入参
当我们创建一个需要读文件的函数时,传递一个文件名作为入参并不合适,比如单元测试的时候就很难写。
比如我们编写一个读取行数的函数,我们需要覆盖3种case:正常case/空文件/只有空行的文件。那我们就需要创建3个文件在单元测试中。
所以比较好的方式是使用io.Reader作为参数。
defer 参数和不同 receiver
我们的一个函数需要调用两个函数foo和bar。同时,它必须处理关于执行的状态:
- 如果foo和bar都没有返回错误,则状态为StatusSuccess
- 如果foo返回错误,则为StatusErrorFoo
- 如果bar函数返回一个错误,则为StatusErrorBar
1 | const ( |
首先我们声明一个状态变量。然后使用 defer 延迟调用 notify 和 incrementCounter 函数。然而,如果我们尝试使用这个函数,我们会发现无论执行路径如何,notify 和 incrementCounter 总是被调用并使用相同的状态:一个空字符串!
出现这个问题的原因是,参数会立即被评估,而不是在包围函数返回时。在我们的示例中,我们将 notify(status)和 incrementCounter(status)作为延迟函数调用。但是传入的参数 status 将是当前的值,而不是最终的值。
解决方法一,将一个字符串指针传递给延迟函数
1 | func f() error { |
使用 defer 会立即评估参数:在这里,是 status 的地址。status 本身在函数中逐渐更新,但是其地址保持不变。因此,如果 notify 或 incrementCounter使用string指针引用的值,它将按预期工作。
解决方法二,另一种解决方案是在 defer 语句中调用闭包
1 | func f() error { |
因此,在执行闭包时 status 会被计算,而不是在我们调用 defer 时。这种解决方案也是可行的,并且不需要更改notify 和 incrementCounter的签名。
另一种比较容易混淆的就是结构体函数的defer调用。
1 | func main() { |
值传递输出的结果是foo,指针传递输出的结果是bar.
使用 panic
1 | func main() { |
仅在 defer 函数内调用 recover() 以捕获 goroutine panic 是有用的。
什么情况下才适合使用 panic?
在 go 语言中,panic 用于表示真正的异常情况,例如,net/http 包中的 WriteHeader 方法,我们会注意到有一个调用 checkWriteHeaderCode 函数的语句,来检查状态码是否有效
1 | func checkWriteHeaderCode(code int) { |
在 go 语言中,我们应该谨慎使用 panic,只有在特殊情况下才会使用 panic 导致应用程序停止。在大多数其他情况下,应该使用一个函数来处理错误,将错误类型作为最后一个返回参数。
包装 error
自Go 1.13起,%w 可以使我们能够方便地包装错误,一般来说,错误包装的两个主要用途如下
- 给错误添加额外的上下文信息
- 将错误标记为特定的错误
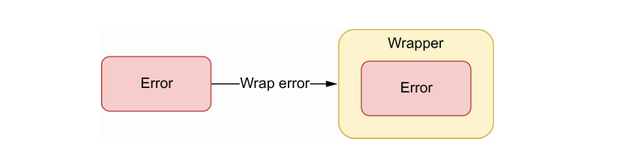
例如,我们收到来自特定用户的请求,访问数据库资源,但在查询过程中出现“权限被拒绝”错误。为了调试目的,虽然最终记录了错误,但希望添加额外的上下文信息。
%v 和%w 的不同之处在于,使用 %v 时错误本身未被包装。而是将其转化为另一个错误以添加到上下文中,源错误不再可用。
检查 error 类型
使用%w指令来包装错误时,我们同样需要改变检查特定错误类型的方式;否则,我们可能会不准确地处理错误。
让我们讨论一个具体的例子。我们将编写一个HTTP处理程序,以返回ID对应的交易金额。我们的处理程序将解析请求以获取ID,并从数据库(DB)中检索金额。我们的实现可能会有两种失败情况:
- ID 无效(字符串长度不等于五个字符)
- 查询数据库失败
在前一种情况下,我们想要返回 StatusBadRequest(400),而在后一种情况下,我们想要返回ServiceUnavailable(503)。
1 | func getTransactionAmount(transactionID string) (float32, error) { |
判断错误类型时:
1 | func handler(w http.ResponseWriter, r *http.Request) { |
当我们运行代码,并且 getTransactionAmountFromDB 发生异常时,HTTP 状态码总是返回 400?这是怎么回事呢?
这事因为 getTransactionAmount 返回的不是 transientError,而是封装 transientError 的一个错误。因此 switch case 匹配时, 不能匹配到 transientError。
解决这个问题,我们应该使用 errors.As,errors.As 是一种检查包装错误是否是某种类型的方法。该函数递归地取消包装错误,并在错误链中匹配相对应的错误,当匹配到时则返回 true。上述代码改为如下所示即可:
1 | func handler(w http.ResponseWriter, r *http.Request) { |
errors.As 函数要求第二个参数(目标错误)为指针。否则,该函数会编译但在运行时会抛出异常。
检查 error 值
项目中有很多已知的error,属于是预期之内的。比如:
sql.ErrNoRowsio.EOF
我们常常使用 ==去检查error的值,但当error被%w包装之后,这样判断就会有问题。这个时候我们就需要使用errors.Is.他会递归unwrap,然后依次比对错误链上的值。
1 | err := query() |
error 被处理多次
一个error处理多次在项目中很常见,比如下面的例子:
1 | func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) { |
当传入 200 时,会发现错误被处理的两遍。分别在 validateCoordinates 中和 GetRoute 中。1
22021/06/01 20:35:12 invalid latitude: 200.000000
2021/06/01 20:35:12 failed to validate source coordinates
良好的习惯是,错误应该只被处理一次。记录错误是处理错误的一种方式,返回错误也是如此。因此,我们应该记录或返回错误,而不是两者同时进行。
更新后的代码如下:
1 | func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) { |
validateCoordinates 返回的每个错误现在都被包装起来,以提供错误的附加上下文。以携带上下文信息:
1 | 2021/06/01 20:35:12 failed to validate source coordinates: |
这样,不会丢失任何有价值的信息。此外,每个错误只处理一次,这简化了我们的代码,避免重复的错误信息。
不需要处理的 error
当我们不需要处理error的时候,经常会那么写:
1 | func f() { |
这样其实会让读者产生误区,究竟是不需要处理error还是忘记处理了,所以我们可以改为:
1 | _ = notify() |
处理 defer 中的 error
当我们在执行 sql 查询的时候,我们需要 close rows。但是 close rows 时可能出错,我们怎么解决这个问题呢?
1 | const query = "..." |
我们有一种选择是记录 close 的 error。将 rows.Close() 放在 defer 中,如果 close 发生错误就记录一条日志信息。
1 | defer func() { |
那我们如果需要将 close 的错误信息传播给 getBalance,这时该怎么实现呢?
1 | defer func() { |
并发和并行
并行是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。
认为并发一定更快
作为Go开发人员,我们不能直接创建线程,但我们可以创建 goroutine,可以把它们看作应用程序级别的线程。然而,操作系统线程的上下文切换是由操作系统在CPU内核上进行的,而 goroutine 的上下文切换是由Go运行时在操作系统线程上进行。
G - Goroutine(协程)
M - OS线程(代表机器)
P - CPU 核心(表示处理器)
每个操作系统线程(M)由操作系统调度程序分配给 CPU 核心(P)。然后,每个 goroutine(G)在M上运行。 GOMAXPROCS 变量定义了同时执行用户级代码的 M 的数量限制。但是,如果线程在系统调用中被阻塞(例如I/O),则调度程序可以启动更多M。自Go 1.5以来,默认情况下GOMAXPROCS等于可用CPU核心数。
当一个 goroutine 被创建但还不能被执行时;例如,所有其他的 M 已经在执行 G。在这种情况下,Go 运行时会怎么处理呢?答案是排队。Go 运行时处理两种类型的队列:每个 P 一个本地队列和所有 P 共享的全局队列。
例如,下图显示了在 GOMAXPROCS 等于4的四核计算机上给定调度情况:
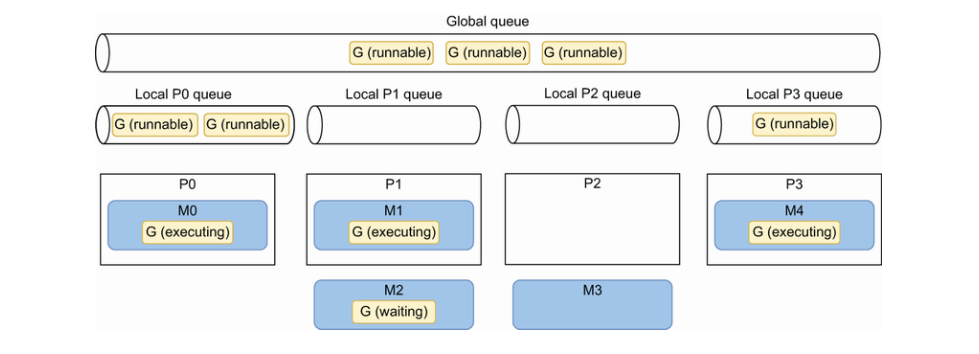
P0、P1和P3正处理忙碌状态。P2 处于空闲状态。
每执行 61 次,Golang 调度器就会检查全局队列中是否有可用的 goroutine。如果没有,就会检查其本地队列。与此同时,如果全局和本地队列都为空,Golang 调度器可以从其他本地队列中挑选 goroutine。这种调度原则称为工作窃取,它允许未被充分利用的处理器积极寻找另一个处理器的 goroutine 并窃取一些。
在 Go 1.14 之前,调度器是协作式的,这意味着仅在特定的阻塞情况下(例如通道发送或接收、I/O、等待获取互斥锁)才能进行 goroutine 切换。从 Go 1.14 开始,Go 调度器现在是抢占式的:当 goroutine 运行特定的时间(10 毫秒)后,它将被标记为可抢占,并可以被切换上下文以替换为另一个 goroutine。这使得长时间运行的作业可以被强制共享 CPU 时间。
协作式调度:
在协作式调度中,goroutines主动让出CPU的执行时间。这意味着一个goroutine执行任务时,它可以选择何时释放CPU,允许其他goroutines执行。
这种方式通常用于编写并发程序,其中goroutines之间需要明确地协调和共享资源。
协作式调度器的优点是可以避免竞态条件和锁的使用,因为goroutines只在明确的时机让出CPU,而不会在任意时刻被强制停止。
编写协作式代码通常更容易理解和调试,但也需要开发人员注意避免长时间的占用CPU,以免阻塞其他goroutines。
抢占式调度:
在抢占式调度中,调度器可以在任何时间中断正在运行的goroutine,并切换到另一个goroutine,无需等待正在运行的goroutine主动释放CPU。
这种方式通常用于需要更好的响应时间和更公平的资源共享的应用程序,例如实时系统或需要处理大量计算密集型任务的应用程序。
抢占式调度器可以确保没有单个goroutine会长时间占用CPU,从而提高系统的响应性。
但是,使用抢占式调度器可能需要更多的开销,因为需要更频繁地进行上下文切换,可能会引入一些竞态条件和锁。
下面使用归并排序来举例:

1 | func sequentialMergesort(s []int) { |
我们编写另一个版本的归并排序,并且使用协程
1 | func parallelMergesortV1(s []int) { |
按道理来说,使用协程的版本会更快!但是结果却相反,第一种传统的方式更快。为什么会这样呢?
这是因为,如果我们有一个包含1024个元素的切片,那么父协程将会启动两个协程,每个协程负责处理512个元素的一半。每个协程都会启动两个新协程来处理256个元素,然后是128个,依此类推。这是因为协程需要的开销太大了,还不如传统的方式来运行。
另外一种解决方法是,定义一个阀值,当高于这个阀值时我们使用协程来并行处理。当低于阀值时我们使用传统的方式来处理
1 | const max = 2048 ❶ 定义阀值 |
1 | Benchmark_sequentialMergesort-4 2278993555 ns/op # 第一种方式 |
这种方法比第一种要快 40% 左右。所以也并不是所有场景下都是并发更快!
何时使用通道或互斥锁来解决并发问题
互斥锁和通道具有不同的语义。每当我们想共享状态或访问共享资源时,互斥锁确保对该资源的独占访问。相反,通道是一种进行信号传递的机制。协调或所有权转移应通过通道实现
即一般来说,并行 Goroutine 需要同步,因此需要使用互斥锁。相反的,同时执行的 Goroutine 通常需要协调管理,因此需要使用通道。
race 问题
数据竞争
我们来看一个数据竞争的问题:
1 | i := 0 |
当我们使用 -race 来运行时,会检测出 data race
1 | ================== |
我们该如何避免数据竞争呢?第一种选择是让增量操作变为原子操作,即在单个操作中完成:可以使用sync/atomic包来进行原子操作。下面是一个如何原子地递增int64的示例
1 | var i int64 |
sync/atomic 包提供了 int32、int64、uint32和uint64的原语,但不支持int。
另一种选项是使用像互斥锁(mutex)这样的特殊数据结构来同步两个 goroutine
1 | i := 0 |
另一个可能的选项是避免共享相同的内存位置,而是跨 Goroutine 进行通信
1 | i := 0 |
每个 goroutine 通过通道发送通知,告知我们应将 i 增加 1。父协程收集通知并增加 i。由于它是唯一一个写入 i 的协程,因此该解决方案也避免了数据竞态。
内存模型
创建 Goroutine 是在 Goroutine 执行开始之前发生的。因此,先读取一个变量,然后启动一个新的 Goroutine 来写入这个变量,不会导致数据竞争
1 | i := 0 |
相反,一个 goroutine 的退出不能保证在任何事件之前发生。因此,下面的示例存在数据竞争
1 | i := 0 |
一个通道上的发送操作发生在相应的接收操作完成之前。在示例中,父 goroutine 在发送前递增了一个变量,而另一个 goroutine 在通道读取后读取了该变量
1 | i := 0 |
关闭一个通道是在收到它被关闭之前
1 | i := 0 |
无缓冲通道的接收操作发生在发送操作之前
1 | i := 0 |
因为来自无缓冲通道的接收操作发生在发送操作之前,因此对 i 的写操作将始终在读操作之前发生。
https://colobu.com/2021/07/13/Updating-the-Go-Memory-Model/
Context
context.WithTimeout
1 | type publishHandler struct { |
这段代码使用 context.WithTimeout 函数来创建一个上下文。这个函数接受一个超时时间和一个上下文为参数。在这里,由于 publishPosition 没有收到一个现有的上下文,我们通过 context.Background 创建了一个新的上下文。同时,context.WithTimeout 返回两个变量:所创建的上下文和一个被调用后会取消上下文的取消函数 cancel func()。将创建的上下文传递给 Publish 方法应该能在最多4秒内使其返回。
context.WithCancel
Go语言上下文的另一个用例是传递 cancel 信号,我们想创建一个应用程序,在另一个goroutine中调用CreateFileWatcher(ctx context.Context, filename string)。这个函数创建了一个特定的文件监听器,它一直从文件中读取并捕获更新。当提供的上下文过期或被取消时,此函数会处理它以关闭文件描述符。
1 | func main() { |
当 main 函数返回时,它调用 cancel 函数来取消传递给 CreateFileWatcher 函数的上下文,使文件描述符可以正常关闭。
context.WithValue
Go语言上下文的另一个用例是携带键值列表,可以通过以下方式创建传达值的上下文
1 | ctx := context.WithValue(parentCtx, "key", "value") |
我们可以使用Value方法来访问该值:
1 | ctx := context.WithValue(context.Background(), "key", "value") |
提供的键和值可以是任何类型。实际上,对于值,我们可以传递任何类型。但为什么键也要是一个空接口而不是一个字符串?这事因为这么做,可能会发生碰撞:来自不同包的两个函数可能使用相同的字符串值作为键。因此,后者会覆盖前者的值。因此,在处理上下文键时的最佳实践是创建一个未导出的自定义类型:
1 | package provider |
Done 和 Err
context.Context 类型导出一个Done方法,该方法返回一个只读通知通道:<-chan struct{}。当与上下文相关的工作应被取消时(截止时期关闭或者调用 cancel取消),此通道将关闭。
此外,context.Context 导出了一个 Err 方法,如果 Done channel 尚未关闭,则返回 nil。否则,它将返回一个非 nil 的错误,如果通道被取消,则返回context.Canceled错误。如果上下文的截止日期已过,则会出现 context.DeadlineExceeded 错误。
1 | func handler(ctx context.Context, ch chan Message) error { |
🎡总结
正如我们所提到的, context 允许我们携带截止时间、取消信号和/或键值列表。一般而言,用户等待的函数应该接受 context 作为参数,这样可以上游调用者可以决定在何时取消调用此函数。
如果对于应该使用哪种上下文感到疑惑,我们应该使用context.TODO()代替传递空的context.Background上下文。
错误的传递 context
有一个函数,接收 HTTP 请求,并在 doSomeTask 中构建 response 响应。然后在响应写入 kafka 中,并且将响应返回。
1 | func handler(w http.ResponseWriter, r *http.Request) { |
附加到 HTTP 请求的上下文可能会在以下场景被取消:
- 当客户端的连接被关闭时
- 在 HTTP/2 请求的情况下,当请求被取消的时候
- 当响应已经被写回客户端的时候
当是第三种情况的时候,如果响应是在 kafak publish 之后写的,这种情况下没有问题。但是如果响应是在 kafka 发布之前或者 publish 期间写的,那么 kafka 发布消息就会失败。
那么如何解决这种问题呢?
第一种解决方法是不传播父级的 context 上下文,反而我们会使用空上下文。
1 | err := publish(context.Background(), response) ❶ 使用空的上下文而不是 HTTP 请求上下文 |
第二种解决方法是我们实现自己的上下文,但是不携带 cancel 的信号,并且能解决第一种解决方案中的使用空的上下文不能在其中传递值的问题。
context.Context 是一个包含四个方法的接口
1 | type Context interface { |
我们自己实现的 context 如下:
1 | type detach struct { ❶ 自定义结构体,封装 context |
自己实现的 context 除了调用父级上下文检索值的 Value 方法之外,其他方法都返回默认值,因此上下文永远不会被视为已过期或已取消。
使用时,我们将自己实现的 context 传递就去即可:
1 | err := publish(detach{ctx: r.Context()}, response) ❶ 传入自己实现的 context |
现在传递给发布函数的上下文将永不过期或被取消,并且它将携带父级上下文的值。
何时停止 Goroutine
Goroutine 的最小堆栈大小为 2 KB,可以随需要增长和缩小(64 位系统上的最大堆栈大小为 1 GB,32 位系统上为 250 MB)
让我们来看一个例子,其中 goroutine 的停止时间点不明确,创建的 Goroutine 会在 ch 被关闭时退出。但我们确切知道这个 channel 何时关闭吗?这可能不明显,因为 ch 是由 foo 函数创建的。如果这个 channel 从未被关闭,就会造成资源泄漏。
1 | ch := foo() |
我们再来看另外一个例子,这段代码的问题在于当主 goroutine 退出时(可能是由于操作系统信号或者因为它有有限的工作负载),应用也会停止。因此,由监听器创建的资源并没有被优雅地关闭。
1 | func main() { |
那我们怎么解决这个问题呢?一个选项是将一个在 main 返回时将被取消的上下文传递给 newWatcher。例如下面这样:
1 | func main() { |
但是这样有个问题,问题在于我们使用信号来传达 goroutine 需要停止运行的消息。我们没有在资源被关闭之前阻塞父级 goroutine。我们需要确保阻塞父级 goroutine 直到资源被关闭,不然就可能发生父级 goroutine 结束了,w.watch 还没被关闭的情况。
所以正确的做法是,我们应该调用 w 的 close 方法来关闭资源
1 | func main() { |
现在我们可以通过使用 defer 来调用这个 close 方法,以确保在应用程序退出之前关闭资源,而不是通过向 watcher 发送信号来关闭其资源。
range 中执行协程
1 | s := []int{1, 2, 3} |
这段代码的输出不是确定性的。例如,有时它会打印出 233,而其他时候则会打印出 333。这是什么原因呢?
这是因为在这个例子中,我们通过闭包创建新的 goroutine。它引用了外部变量:这里是变量 i。我们必须知道当闭包 goroutine 执行时,它并不捕获创建 goroutine 时的值。相反,所有 goroutine 都引用相同的变量。
那该怎么解决呢?
第一个选择,如果我们仍要使用闭包,涉及创建一个新变量:
1 | for _, i := range s { |
在每次迭代中,我们会创建一个新的局部变量 val。这个变量捕获了当前迭代中的 i 值,在协程创建前。因此,当每个闭包协程执行打印语句时,都会使用预期的值。这段代码会打印出 123。
第二个选项不再依赖闭包,而是使用实际的函数:
1 | for _, i := range s { |
这种方法不是闭包,该函数不引用来自其主体外部的变量 val;val 现在是函数的一部分输入。通过这样做,我们在每次迭代中都固定了i。
switch+channel 的随机选择
下面例子中,我们希望先处理 messageCh 通道中的内容,然后在处理 disconnectCh 中的内容,代码如下:
1 | for { |
测试用例如下:
1 | for i := 0; i < 10; i++ { |
但是得到的结果如下,并没有打印10条消息,然后在处理 disconnectCh。
1 | 0 |
出现这样的原因是,当有一个或者多个通道可以处理时,那么将通过伪随机选择选一个通道进行处理。这么做的好处是防止饥饿。
那么假如我们要实现上述的需求【⚠️上述的需求中有多个 goroutine 生产者】,那么该怎么实现呢?下面是一种解决方式:
1 | for { |
该解决方案使用一个带有两个 case 的 for/select:一个是 messageCh,另一个是默认情况。只有在没有其他 case 匹配时,才会在 select 语句中使用 default。在这种情况下,这意味着我们只有在接收到 messageCh 中所有剩余的消息后才会返回。
⚠️这么做能保证顺序的前提是 messageCh 的消息是一次性发送完成的,而不是分开发送,这样在执行第二个从 messageCh 中读取消息时,肯定会有数据,而不是先执行 default。
另一种情况下,如果是单个 goroutine 作为生产者的情况下,我们则可以使用不带缓冲区的 channel 来达到目的。
使用 channel 作为通知信道
在Go语言中,一个空结构体是一个没有任何字段的结构体。无论架构如何,它占用零字节的存储空间,我们可以使用unsafe.Sizeof验证:
1 | var s struct{} |
为什么不使用一个空接口(var i interface{})?因为一个空接口是有大小的;它在32位架构上占用8字节,在64位架构上占用16字节。
一个没有数据的信道应该用 chan struct{} 类型来表示。这样一来,就可以为接收者明确表示,他们不应该从消息内容中期望任何含义——只是表示他们已经接收到了一条消息。在Go中,这些信道被称为通知信道。
nil channel
1 | var ch chan int ❶ nil chanel |
ch 是 chan int 类型。channel 的零值为 nil,因此 ch 为 nil。协程不会触发 panic;但是,它将一直阻塞。
如果我们向一个 nil 的通道发送消息,原理是一样的。这个 goroutine 会永远阻塞:
1 | var ch chan int |
nil channel 有时候很有用,我们可以使用 nil 通道来实现一种优雅的状态机,从而将一个 case 从 select 语句中去除。例如一下示例:从两个通道接收。如果其中一个关闭,我们将其赋值为nil,因此我们只从一个通道接收。
1 | func merge(ch1, ch2 <-chan int) <-chan int { |
在 Go 的
select语句中,如果多个case中的通道都是可读的(或者都是可写的),选择哪个case是非确定性的。当其中一个通道为nil时,它被视为不可读(或不可写),而select语句会自动选择其他可读(或可写)的通道来执行。
有/无缓冲的 channel
一个非缓存信道是没有容量的信道。它可以通过省略大小或提供零大小来创建
1 | ch1 := make(chan int) |
使用无缓冲信道(有时称为同步信道),发送者将一直阻塞,直到接收者从信道接收到数据
相反地,带缓冲的通道具有容量,必须创建一个大小大于或等于1的通道:
1 | ch3 := make(chan int, 1) |
有了缓冲通道,发送者可以在通道未满的情况下发送消息。一旦通道满了,它将阻塞直到接收者协程收到了一条消息。例如:
1 | ch3 := make(chan int, 1) |
append的时候 data races
对切片使用 append 添加元素一定会产生数据竞争吗?并不一定!需要分场景。
在下面的例子中, 我们将初始化一个slice并创建两个goroutines,这些goroutines将使用append创建一个具有额外元素的新 slice:
1 | s := make([]int, 1) |
这个例子会造成数据竞争吗?答案是不会。因为 slice 有两个属性,长度和容量。长度是 Slice 中可用元素的数量,而容量是支持数组中元素的总数。当我们使用 append 时,行为取决于 Slice 是否已满(长度 == 容量)。如果是,Go 运行时会创建一个新的数组以添加新元素;否则,运行时将其添加到现有的支持数组中。
在上述例子中,我们创建了一个长度和容量都为1的切片。因此,由于切片已经满了,所以在每个 goroutine 中使用 append 都将返回一个底层为新数组的切片。它不会改变现有的数组,所以不会产生数据竞争。
假如我们更换一下初始化方法,不在创建长度为1的切片,而是创建长度为0的但容量为1的切片
1 | s := make([]int, 0, 1) // 长度为0,但容量为1的切片 |
这样是否为造成数据竞争呢?答案是会。我们使用 make([]int, 0, 1) 创建一个切片,因此数组并没有被填满。两个 goroutines 都试图更新支撑数组的同一个索引(索引 1),这就会导致数据竞争。这时,我们应该怎么处理呢?我们可以创建 s 的副本来解决这个问题:
1 | s := make([]int, 0, 1) |
两个 goroutine 都会复制切片,然后它们在各自的切片副本上使用 append,而不是原始切片,这样就可以防止数据竞争。
🎡总结
- 访问相同的切片个索引,并且至少有一个 goroutine 在更新值时,这将会引起数据竞争。
- 访问不同的切片索引不会导致数据竞争,不同的索引意味着不同的内存位置。
- 访问同一个 map(无论是相同的键还是不同的键)且至少有一个 goroutine 更新它,就会产生数据竞争。这是因为 map 的底层实现是一个哈希表(hash table),它包含了桶(buckets)和哈希函数。当你向 map 中插入或检索数据时,Go 会使用键的哈希值来确定数据在哪个桶中。即,在并发情况下,多个goroutine同时对map进行操作时,可能会造成多个goroutine同时读写同一个哈希桶,导致数据竞争的问题。例如,多个goroutine同时向同一个桶中插入数据,可能会导致插入的数据被覆盖或者丢失,从而破坏了map的正确性。
- 通常情况下,我们不应根据切片是否已满来采用不同的实现。我们应该考虑到,在并发应用程序中对共享切片使用 append 可能会导致数据竞争。因此,应避免这种情况。